





过去一两年的时间里,以大语言模型(LLM)为代表的人工智能(AI)技术无疑是最受公众关注的话题。尤其涉及到美国对英伟达等芯片企业出口中国的限制,已然打响了又一轮无声的“冷战”。
在另一块生物科技的“战场”,中美双方出现了新的矛盾:美国总统拜登签署了《关于防止关注国家(countries of concerns)批量获取美国个人及政府敏感信息的行政令》,“关注国家”自然包括中国,而敏感信息之一则是人类基因组信息。
这个矛盾在刚刚过去的美国时间3月6日达到了“高潮”。美国参议院国土安全与政府事务委员会近日召开听证会,以11比1的同意票数通过了参议院版的“生物安全法案”草案,目的在于禁止美国联邦政府与某些与外国竞争对手有联系的生物技术提供商签订合同。被“点名”的中国企业包括华大系、药明系等。
事实上,这并不是国家之间首次限制彼此人类基因组信息的交流。2019年,我国出台了《中华人民共和国人类遗传资源管理条例》,并在其中多项条款规定限制外国对中国人类遗传数据的使用。
对于大多数公众来说,可能没那么容易理解:基因组数据,至于要这么严格吗?国家与国家之间,真的有必要相互封锁吗?
20多年前的约定
这个故事可能得从28年前的一场会议讲起。
1996年,参与人类基因组计划(Human Genome Project,HGP)的科研人员齐聚大西洋上的百慕大岛屿,共同商量一件过去科学家从来没有想过的事情:基因组数据要怎么共享?
在上个世纪,生物学实验相对简单,不论结果再怎么多,往往一张表格就能放下。但是基因组测序不同,以最简单的病毒、细菌、酵母或古菌为例,它们的基因组不大,但是打印出来少说也得几十甚至上千页。
而彼时已经开展了6年的人类基因组计划,预计有3000000000个碱基,倘若发表出来,就是一本写满ATCG的超级大词典。这在过去的生物研究历史中,闻所未闻。
当时的人类基因组计划是一项世界级的工程,来自美国、英国、法国、中国的科学家需要分工协作。只有及时更新数据库,大家才能第一时间知道项目的进展。其他科学家也能尽快根据自己感兴趣的内容,开展相关的研究。
基于此,这些科学家最终达成了一个即便放在今天,都是令人震撼和感慨的共识:数据产生的24小时内,就要分享到数据库让全世界看到,而且是完全免费开放。
2003年,随着人类基因组计划的初步完成与基因组数据的增多,新的“劳德代尔堡协议”达成,在过去“百慕大原则”的基础上,进一步支持了合作项目间基因组数据的及时分享,并构建了一个更完善的责任制度,更好地支持基因组数据的产生与使用。二者被认为是基因组数据开放使用的开端,也深深影响了后来二十年间基因组研究的数据共享方式。
得益于“即时共享”的核心思想,本来预计需要15年完成的人类基因组计划,整整提前了四年。时至今日,世界主流的几个基因组数据库,例如美国的国家生物技术信息中心(NCBI)、英国的生物银行(UK BioBank),以及中国的国家基因组科学数据中心,都包含了成百上千万的人类基因组信息,以及百万物种的基因组数据,而且这些信息的访问和获取全部免费。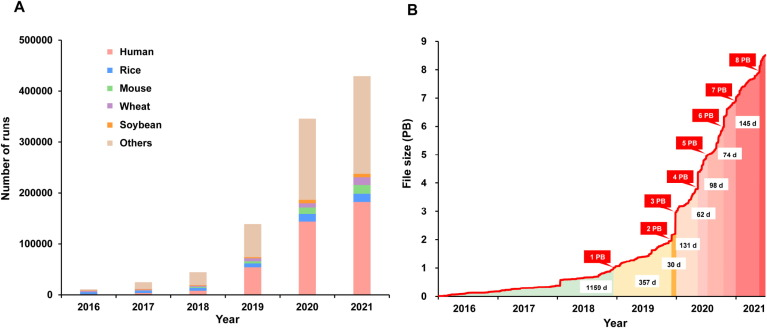
于是,一家单位发布了基因组,另一家单位就能快速下载下来,并在前人的基础上补充更丰富的分析,或者添加更具体的实验。基因组学,甚至说生物学的大厦,就是通过这种数据开放的方式在这20年里一砖一瓦搭建起来的。
基因组的发表已经大不相同
但随着数据的增多,科研人员相互之间的竞争也越发激烈,基因组数据的发表方式逐渐发生了变化:
首先,考虑到文章发表的时效性,以及与其他研究者的冲突,第一时间给世界共享数据在今天已经很少见了,作者至少要确保自己的文章和成果成功发表,才会在数据库上传数据。
其次,很多大型的基因组数据不会简单释放开来,你想要使用的时候需要给负责人提交申请,而每一家负责单位对申请的考核标准都不一样,很可能因为各种原因遭受拒绝。
另外,伴随着测序费用的降低,基因组原始文件越来越大,个别单个大项目的数据已经不是以GB、TB为单位,而是以更高的PB为单位了(1024个TB)。研究人员为了“省事”,更乐意上传一些中间文件数据,甚至只上传部分他们觉得有必要的数据。至于其他原始数据和细节,你就得单独想办法去要了。
“共享遗传信息”的做法曾加速生命科学的发展,但随更多社会、政治等因素的介入,也不得不被踩下刹车。尤其到了最近几年,国家开始干预基因组数据的分享,例如前面提及的美国、中国颁布的一系列法案条规。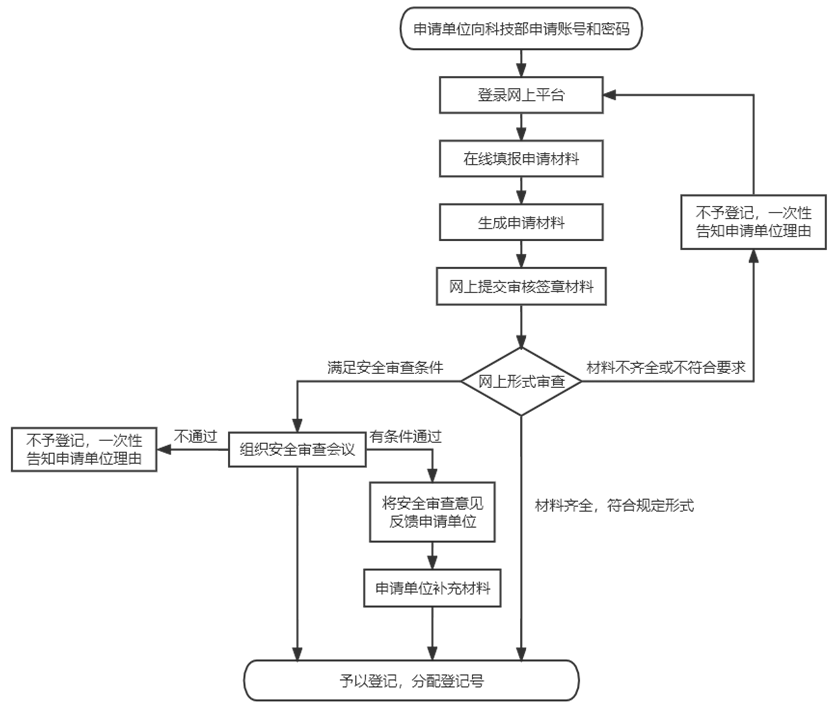
国内人类遗传数据对外提供申请的流程
如今在中国,一份人类遗传学数据的产生到发布,你需要经历:项目申请的审批,采样前的审批,国外研究人员合作的审批(如有),数据提交的审批与备份……通过这样一系列的过程,你的数据才能被“半公开”。海外科学家想要使用的话,需要向中国数据库提交申请,获批后方能获取。
美国则是提出了一套更有“针对性”和“目的性”的法案——特定国家的科学家不能随意使用其人类基因组信息。当然,是否执行、以及未来会如何执行,可能都还是未知数。
基因组泄露,关键问题在于个人安全
为什么国家要下场干预基因组数据的共享与开放?原本透明、公开、开放的信息体系不好吗?一同搭建全人类的生物学研究“大厦”不好吗?
美国政府官网是这样说的:
总统的行政命令重点保护美国人最私密和最敏感的个人信息,包括基因组数据、生物特征数据、个人健康数据、地理位置数据、财务数据和某些类别的个人身份信息。不良行为者可以利用这些数据追踪美国人(包括军事人员),窥探他们的个人生活,并将这些数据传给其他数据经纪人和外国情报机构。这些数据可能导致侵入性监视、诈骗、勒索和其他侵犯隐私的行为。
中国的《人类遗传资源管理条例》第二十八条则是这样说的:
二十八条 将人类遗传资源信息向外国组织、个人及其设立或者实际控制的机构提供或者开放使用,不得危害我国公众健康、国家安全和社会公共利益;可能影响我国公众健康、国家安全和社会公共利益的,应当通过国务院科学技术行政部门组织的安全审查。
不难看出,双方共同的关注重点在于个人/公众安全。
这里的安全涉及到很多方面,最直接的问题是隐私安全问题。这也是我们每个人需要关注的问题——不论国家封不封锁,我们都应该注重个人的基因组隐私,毕竟这可能比指纹或者面容信息都要重要。
可以想象一下,如果你的身高、体重、三围和疾病史,在你不知情时,被千里之外一个奇怪的实验室拿来研究、发表文章、被公开给全世界,甚至创造一个和你一样的克隆人……这还是非常骇人听闻的。
虽然科研人员在发表数据时会专门隐去志愿者的具体姓名信息,但从技术层面看,基于基因组溯源到个人身份信息是可行的,有一项研究就曾利用千人基因组项目的数据和网络信息,找到了其中50个人的名字。
因此对数据库设定层层访问审查,保证提供数据的志愿者的全面知情同意,也都是必须的。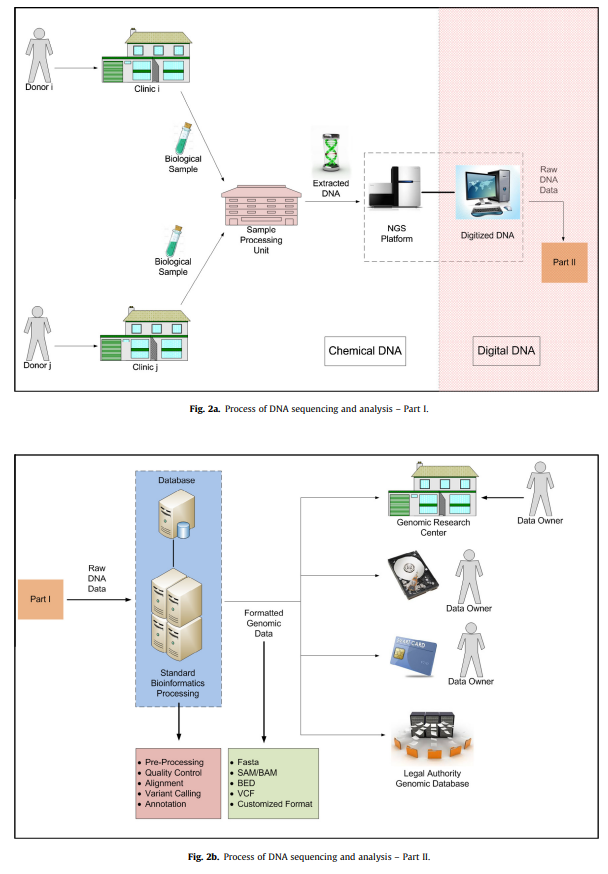
基因组数据产生与后续分析的基本流程,从样本、比对、测序、数据释放,每一步都有可能发生隐私泄露的风险
而另一个大家普遍担心的问题,是人身安全,换言之则是生物武器的可能性,更具体点是基因武器。
小说《三体》里展示了这样的一种技术:主角罗辑为了保护自己,藏身于军方的地下基地,但却还是被敌人设计的,专门只感染他的致命病毒感染,差点丧命。这样的剧情在今天,可能实现吗?
除了同卵双胞胎,任意两个人的基因组都是不一样的,平均差异大约是0.1%,对于拥有30亿个碱基的人类基因组来说,那就是300万个碱基,这不是一个小数目。
即便是一个碱基的差异,都可能为生物武器提供“机会”。而如今伴随着生物合成技术和生物信息分析方法的快速发展,一方面从头合成制造病毒、支原体、细菌、酵母已经纷纷实现,另一方面AI设计、辅助生产特定蛋白质,基因组快速比对也已经是科研上的常规操作——二者一结合,小说里的情节就能照进现实。
这也是美国、中国急于颁布相关法规的原因之一了。而限制生物数据的访问,以保护隐私与放权的做法,必然是未来的趋势。
100%的“遗传封锁”并不可取
但是我们也不难发现,其实各国的“封锁”并不是一种100%的限制,而是受控访问。比如中国的《人类遗传资源管理条例》强调的是加强监管,美国近期的法案草案也没有完全限制中国全部科研单位。
因为相比20年前“人类基因组计划”时期,今天数据产生的速度、技术迭代更新的速度都今非昔比,大量的数据产生、大量生物医学问题得以解析——此时不能,也完全不应该限制不同国家科研人员之间的数据访问。任何一方的限制,从科学研究与技术发展的角度考虑,都会成为极大的阻碍。
与之相应的是科学问题对数据的“如饥似渴”——人类基因组研究最常见的全基因组关联分析(GWAS),动辄就需要上万人的基因组数据,其产生、分析与数据存储成本以“亿元”为单位;人类疾病的诊疗往往涉及大量潜在的基因突变位点,想要研究清楚也需要海量数据的支持;而在未来想要实现个性化的精准医疗,对于个人的基因组分析也是必不可少的……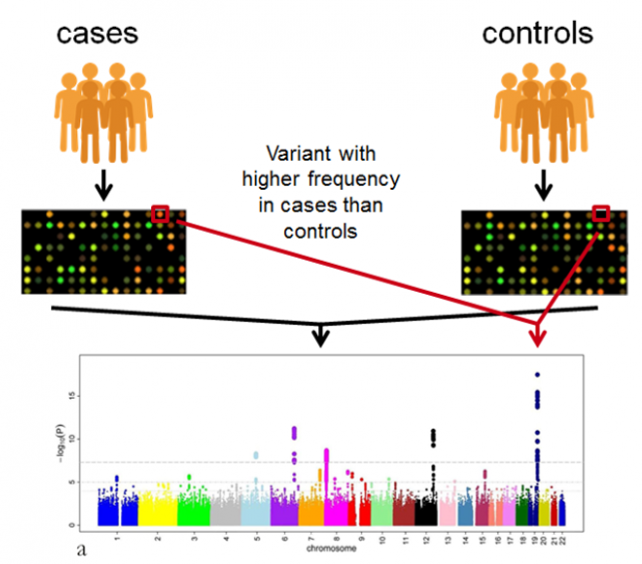
GWAS的分析原理是基于大样本量的基因组比较,从30亿个碱基位点里筛选出与某个表型性状有关的基因,这就要求有足够的样本量结果才具有意义
面对这些问题,最有效、最具性价比的方式,就是展开合作与数据共享。因此,如何在“开放数据、促进科研”和“保护隐私、保护个人安全”之间取得平衡,就是如今生物医学研究者继续探讨的问题。过去的“百慕大原则”与“劳德代尔堡协议”已经有些过时,我们需要一套更符合当下的制度。
但这也是一个涉及科学、伦理、道德、法律、政治、国家、社会、个人的复杂问题,单靠某个国家的政策其实并非长久之计。一方面需要各国各行各业的人们坐下来一起协商,像过去一同约定禁止生物武器一样,通过一致的协定尽可能地规避基因组研究带来的生物风险;另一方面,还应该进一步完善统一的审核与开放使用标准,提高数据的加密算法,让研究者能以最快且最安全的方式开展科学研究。
令人振奋的是,已经有不少科研人员在尝试这一方面的努力:2013年成立的全球基因组学与健康联盟就在尝试联合全世界的基因组数据库,让数据共享的规定达成一致;不少国家的研究者也开发了多种加密算法,比如同态加密等方法,确保数据的安全和可用性……
未来的数据是共享还是封锁?科学与技术的发展,社会与规定的完善,会给出答案。
参考资料:
Powell K. The broken promise that undermines human genome research[J]. Nature, 2021. 590(7845): 198-202.
Wang S, Jiang X, Singh S, et al. Genome privacy: challenges, technical approaches to mitigate risk, and ethical considerations in the United States[J]. Annals of the New York Academy of Sciences, 2017. 1387(1): 73-83.
Chen T, Chen X, Zhang S, et al. The genome sequence archive family: toward explosive data growth and diverse data types[J]. Genomics, Proteomics and Bioinformatics, 2021. 19(4): 578-583.
缺乏数据使用指导原则,基因组数据共享遇阻. 中国科学报,更多股票资讯,关注财经365!





